Hadoop Admin Ansvar
Den här bloggen om Hadoop Admin-ansvar diskuterar omfattningen av Hadoop-administrationen. Hadoop-administratörsjobb är efterfrågade så lär dig Hadoop nu!

Den här bloggen om Hadoop Admin-ansvar diskuterar omfattningen av Hadoop-administrationen. Hadoop-administratörsjobb är efterfrågade så lär dig Hadoop nu!
Apache Spark har kommit fram som en stor utveckling inom stor databehandling.
Apache Hadoop 2.x består av betydande förbättringar jämfört med Hadoop 1.x. Den här bloggen talar om Hadoop 2.0 Cluster Architecture Federation och dess komponenter.
Detta ger en inblick i användningen av Job tracker
Apache Pig har flera fördefinierade funktioner. Inlägget innehåller tydliga steg för att skapa UDF i Apache Pig. Här är koderna skrivna i Java och kräver Pig Library
Där består HBase Storage-arkitektur av flera komponenter. Låt oss titta på funktionerna hos dessa komponenter och veta hur data skrivs.
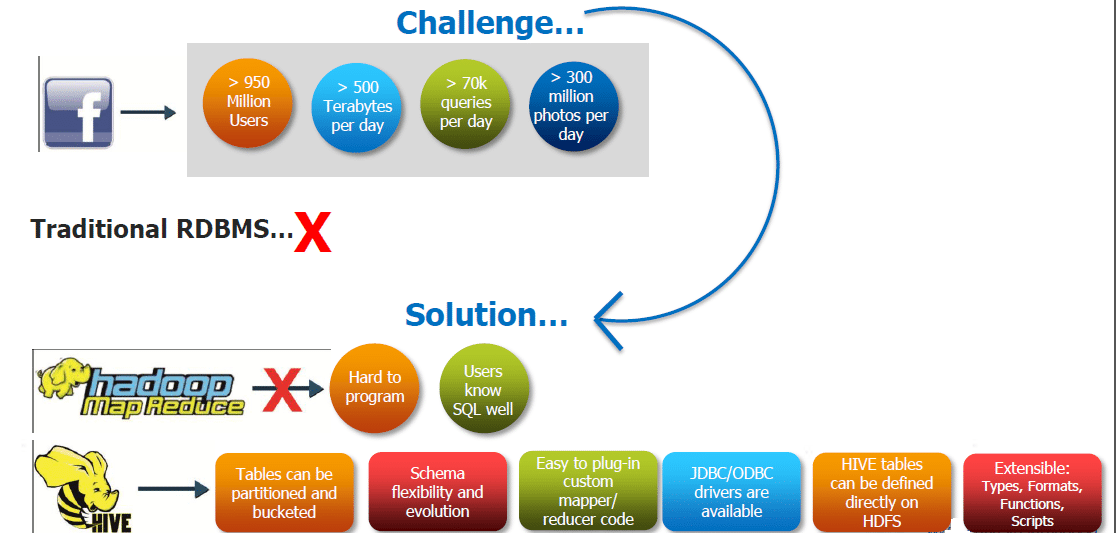
Apache Hive är ett Data Warehousing-paket byggt ovanpå Hadoop och används för dataanalys. Hive riktar sig till användare som är bekväma med SQL.
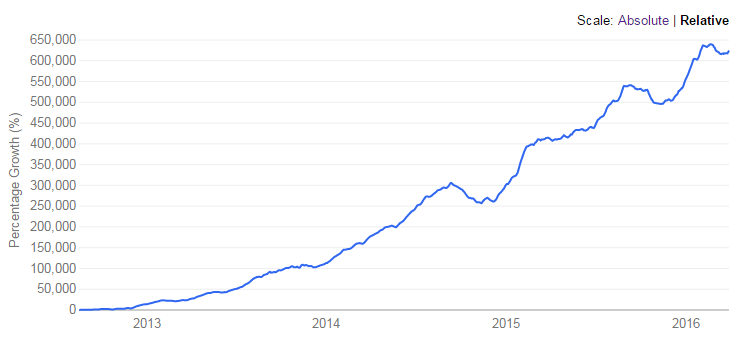
Implementeringen av Apache Spark med Hadoop i stor skala av toppföretag indikerar framgång och dess potential när det gäller realtidsbehandling.
NameNode hög tillgänglighet är en av de viktigaste funktionerna i Hadoop 2.0. NameNode hög tillgänglighet med Quorum Journal Manager används för att dela redigeringsloggar mellan Active och Standby NameNodes.
Hadoop-utvecklarens jobbansvar täcker många uppgifter. Jobbansvar beror på din domän / sektor. Denna roll liknar en programutvecklare
Hive-datamodellerna innehåller följande komponenter som databaser, tabeller, partitioner och skopor eller kluster.Hive stöder primitiva typer som heltal, flottör, dubbel och strängar.
Dessa fyra skäl att uppgradera till Hadoop 2.0 berättar om Hadoop-arbetsmarknaden och hur det kan hjälpa dig att påskynda din karriär genom att göra dig öppen för enorma jobbmöjligheter.
I den här bloggen kommer vi att köra Hive and Garn-exempel på Spark. För det första, bygg Hive and Garn on Spark och sedan kan du köra Hive and Garn-exempel på Spark.
Syftet med denna blogg är att lära sig att överföra data från SQL-databaser till HDFS, hur man överför data från SQL-databaser till NoSQL-databaser.
Cloudera Certified Developer för Apache Hadoop (CCDH) är ett lyft till din karriär. Detta inlägg diskuterar fördelarna, tentamönster, studiehandbok och användbara referenser.
Den här bloggen ger en översikt över HDFS-arkitekturens höga tillgänglighet och hur du konfigurerar och konfigurerar ett HDFS-kluster med hög tillgänglighet i enkla steg.
Apache Kafka fortsätter att vara populär när det gäller realtidsanalys. Här är en titt på det ur en karriärsynpunkt, diskuterar karriärmöjligheter och jobbkrav.
Apache Kafka tillhandahåller hög kapacitet och skalbara meddelandesystem som gör det populärt i realtidsanalys. Lär dig hur en Apache kafka-handledning kan hjälpa dig
Detta blogginlägg är ett djupt dyk i gris och dess funktioner. Du hittar en demo av hur du kan arbeta på Hadoop med Pig utan beroende av Java.
Den här bloggen diskuterar förutsättningar för att lära sig Hadoop, Java-väsentligheter för Hadoop & svar 'behöver du Java för att lära dig Hadoop' om du känner till Pig, Hive, HDFS.