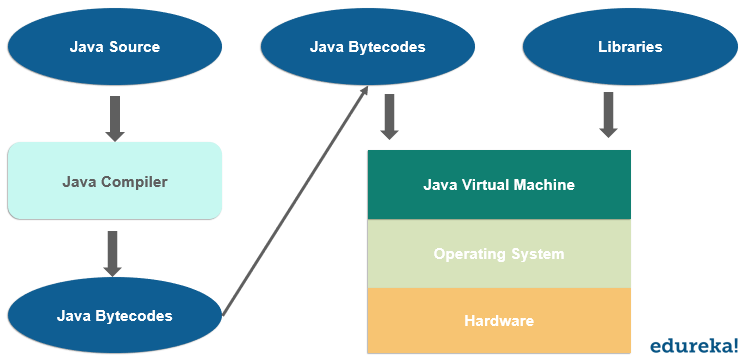
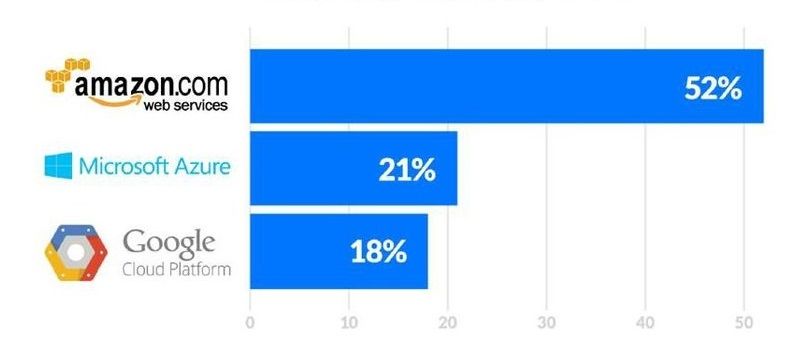
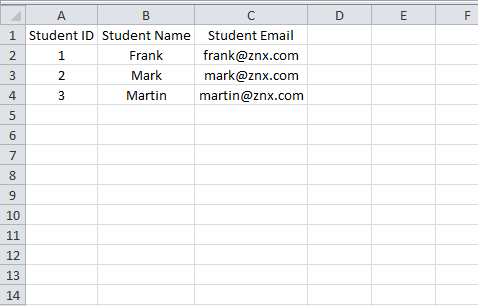
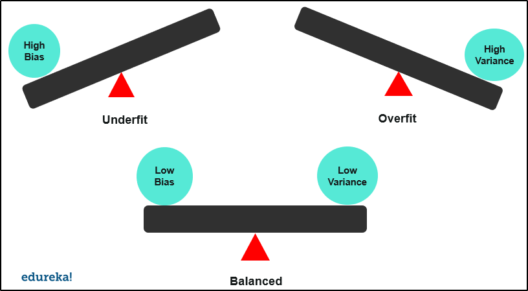
HBase-handledning: HBase-introduktion och Facebook-fallstudie
Denna HBase-handledningblogg introducerar dig till vad som är HBase och dess funktioner. Det täcker också fallstudie på Facebook Messenger för att förstå fördelarna med HBase.

Denna HBase-handledningblogg introducerar dig till vad som är HBase och dess funktioner. Det täcker också fallstudie på Facebook Messenger för att förstå fördelarna med HBase.
Den här bloggen är en guide om hur du installerar Puppet Master och Puppet Agent. Det innehåller också ett exempel för att distribuera Apache Tomcat med Puppet Tomcat Module.
Den här bloggen är en steg-för-steg-guide för Apache Pig Installation i Linux-miljö. Vi installerar Apache Pig 0.16.0 och kör den i olika lägen.
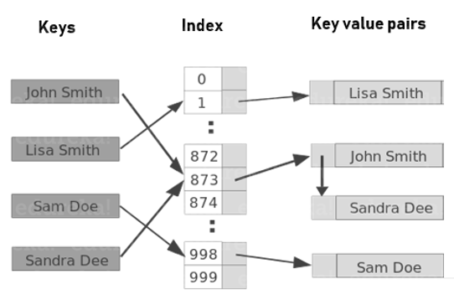
Den här bloggen om HBase Architecture förklarar HBase-datamodellen och ger inblick i HBase Architecture. Det förklarar också olika mekanismer i HBase.
Denna Hive tutorial blogg ger dig fördjupade kunskaper om Hive Architecture och Hive Data Model. Det förklarar också NASA-fallstudien om Apache Hive.
Denna Spark Streaming-blogg introducerar dig till Spark Streaming, dess funktioner och komponenter. Det inkluderar ett sentimentanalysprojekt med hjälp av Twitter.
Denna Spark MLlib-blogg introducerar dig till Apache Sparks maskininlärningsbibliotek. Det inkluderar ett filmrekommendationssystemprojekt med Spark MLlib.
Denna grafiska handledningsblogg introducerar dig till Apache Spark GraphX, dess funktioner och komponenter inklusive ett flygdata-analysprojekt.
Denna blogg för Apache Flume-handledning förklarar grunderna för Apache Flume och dess funktioner. Det kommer också att visa Twitter-streaming med Apache Flume.
Apache Sqoop Handledning: Sqoop är ett verktyg för att överföra data mellan Hadoop och relationsdatabaser. Den här bloggen omfattar import och export av Sooop från MySQL.
Apache Oozie-handledning: Oozie är ett schemaläggningssystem för arbetsflöden för att hantera Hadoop-jobb. Det är ett skalbart, pålitligt och utdragbart system.
Big Data-applikationer revolutionerar organisationer och hjälper dem att fatta mer informativa affärsbeslut genom att analysera stora datamängder.
Apache Spark har tagit över Big Data & Analytics-världen och Python är ett av de mest tillgängliga programmeringsspråken som används i branschen idag. Så här i den här bloggen lär vi oss om Pyspark (gnista med python) för att få ut det bästa av båda världarna.
Den här bloggen fokuserar på Apache Hadoop YARN som introducerades i Hadoop version 2.0 för resurshantering och jobbplanering. Det förklarar GARN-arkitekturen med dess komponenter och de uppgifter som utförs av var och en av dem. Den beskriver ansökans inlämning och arbetsflöde i Apache Hadoop YARN.
I den här bloggen på PySpark Tutorial får du lära dig mer om PSpark API som används för att arbeta med Apache Spark med Python Programming Language.
I den här PySpark Dataframe-handledningsbloggen lär du dig om omvandlingar och åtgärder i Apache Spark med flera exempel.
Denna Edureka-blogg på Cloudera Hadoop Tutorial ger dig en fullständig inblick i olika Cloudera-komponenter som Cloudera Manager, paket, nyans osv.
Detta inlägg beskriver om ökningen av efterfrågan på Hadoop- och NoSQL-färdigheter inom IT och andra områden. läs vidare för att se hur Hadoop och NoSQL färdigheter kommer att hjälpa
Den här bloggen diskuterar fördelarna med Hadoop-implementering, Hadoop-initiativ, Hadoop i små och stora organisationer och karriärfördelar med Hadoop-utbildning.
Hadoop har blivit en het färdighet att förvärva i IT-kretsen, antalet Hadoop-elevers profil ökar drastiskt dag för dag.