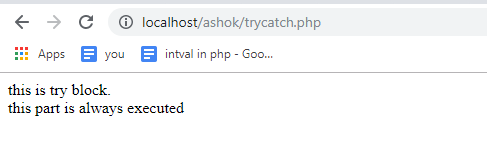
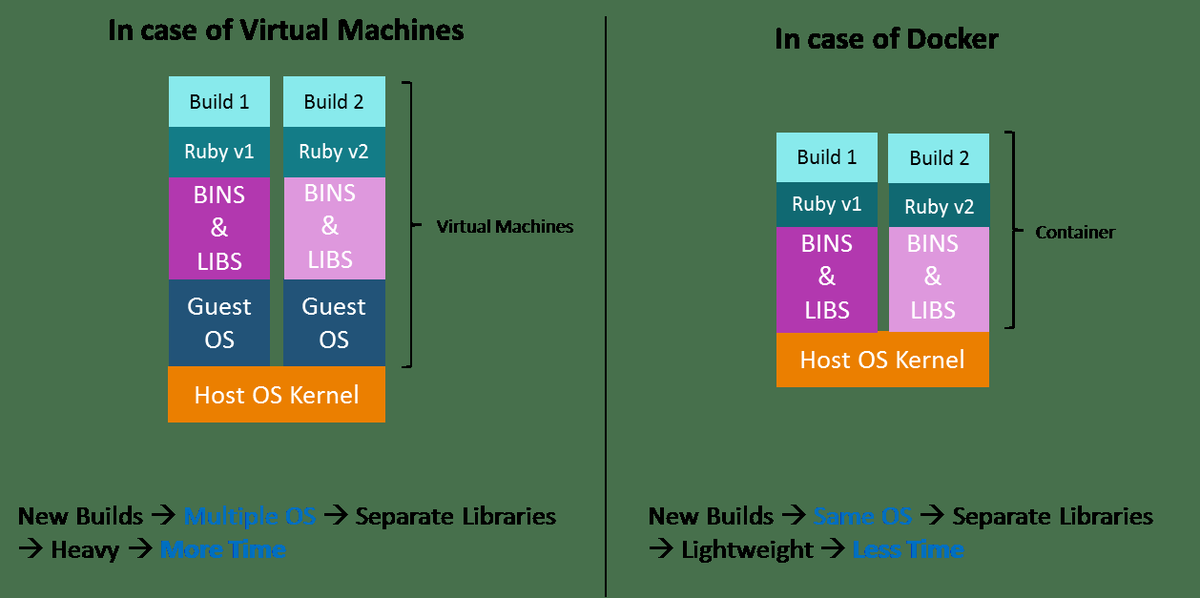
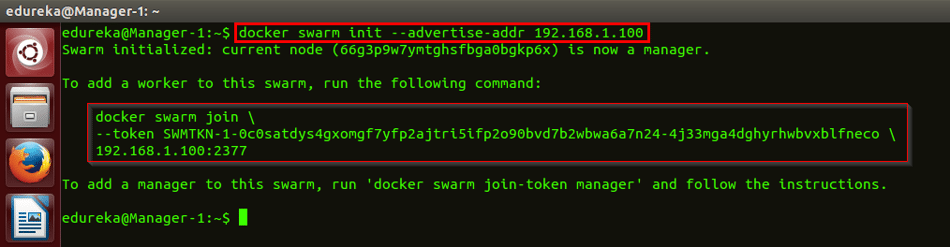
Spark vs Hadoop: Vilket är det bästa Big Data Framework?
Detta blogginlägg talar om apache gnista vs hadoop. Det ger dig en uppfattning om vilken rätt Big Data-ram du kan välja i olika scenarier.

Detta blogginlägg talar om apache gnista vs hadoop. Det ger dig en uppfattning om vilken rätt Big Data-ram du kan välja i olika scenarier.
Den här bloggen hjälper dig att förstå hur du installerar och konfigurerar sbteclipse-plugin med steg-för-steg-instruktioner för att köra Scala-applikationen i Eclipse IDE.
Det här blogginlägget förklarar varför du måste komma igång med Apache Spark efter Hadoop & varför att lära sig Spark efter att ha behärskat hadoop kan göra underverk för din karriär!
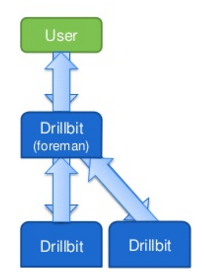
Den här Apache Drill-handboken ger dig all information du behöver för att komma igång med Apache Drill-frågemotorn, användning med Hadoop, Big Data & Apache Spark.
Den här Spark Hadoop-bloggen berättar allt du behöver veta om Apache Spark combineByKey. Hitta medelvärdet per elev med hjälp av combineByKey-metoden.
Apache Falcon är en ny datahanteringsplattform för Hadoop-ekosystemet som förenklar ombordmatning av foderbehandling och foderhantering på hadoop-kluster. Lär dig hur du ställer in det.
Den här Apache Spark-bloggen förklarar Spark-ackumulatorer i detalj. Lär dig användning av gnistackumulator med exempel. Gnistackumulatorer är som Hadoop Mapreduce-räknare.
Lär dig allt om Apache Flink och skapa ett Flink-kluster i den här bloggen. Flink stöder realtids- och batchbehandling och är ett måste för Big Data-teknik för Big Data Analytics.
Det här blogginlägget diskuterar distribuerad caching med sändningsvariabler och du kommer igång med att effektivt distribuera stora värden i Spark-programmering.
CCA- och CCP-certifieringar av Cloudera har ersatt CCDH- och CCSHB-prov. Den här bloggen berättar allt du behöver veta om de nya certifieringarna.
Det här blogginlägget diskuterar stateful transformations with windowing in Spark Streaming. Lär dig allt om spårning av data i flera satser med hjälp av statliga D-Streams.
Det här blogginlägget diskuterar stateful transformations in Spark Streaming. Lär dig allt om kumulativ spårning och kompetens för en Hadoop Spark-karriär.
Hadoop & Big Data-teknologier revolutionerar sjukvårdsanalyser. Den här stora datan i vårdbloggen diskuterar hur stor dataanalys kan förbättra medicinsk vård.
Det här blogginlägget på Hadoop Streaming är en steg-för-steg-guide för att lära dig att skriva ett Hadoop MapReduce-program i Python för att bearbeta enorma mängder Big Data.
Denna blogg om Big Data Tutorial ger dig en fullständig översikt över Big Data, dess egenskaper, applikationer samt utmaningar med Big Data.
Denna HDFS självstudieblogg hjälper dig att förstå HDFS eller Hadoop Distribuerade filsystem och dess funktioner. Du kommer också att utforska dess kärnkomponenter i korthet.
I denna Splunk-handledning ska du förstå skillnaderna mellan Splunk vs. ELK vs. Sumo Logic och bestämma vilka av dessa verktyg som passar dig bäst.
I denna blogg om Splunk-användningsfall kommer du att förstå hur Domino's Pizza använde Splunk för att få konsumentbeteende. Och formulera sina affärsstrategier.
Denna handledning är en steg-för-steg-guide för att installera Hadoop-kluster och konfigurera det på en enda nod. Alla installationsstegen för Hadoop är för CentOS-maskinen.
Den här bloggen talar om de olika HDFS-kommandona som fsck, copyFromLocal, expunge, cat etc. som används för att hantera Hadoop File System.