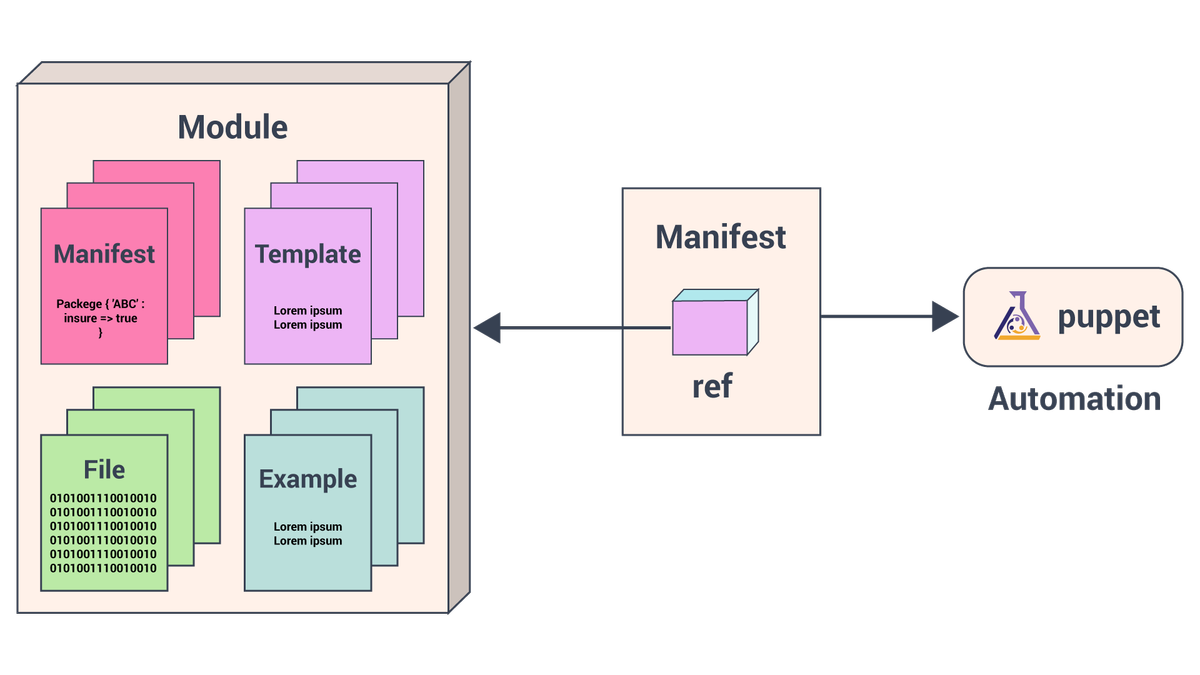
Vilka är de viktigaste terminologierna i Hadoop Security?
Den här Edureka-bloggen hjälper dig med en detaljerad och omfattande kunskap om hadoop-säkerhet som implementeras i realtid.

Den här Edureka-bloggen hjälper dig med en detaljerad och omfattande kunskap om hadoop-säkerhet som implementeras i realtid.
Den här bloggen om Big Data Hadoop-jobb diskuterar Hadoop-jobbmöjligheter och hadoop-utvecklarlön. Ta reda på hur du kan hämta topp-hadoop-jobb om du lär dig hadoop
Den här artikeln i Edureka hjälper dig att förstå de senaste färdigheterna, ansvarsområdena, jobbtrenderna och lönetrenderna hos en Hadoop-utvecklare.
Den här bloggen förklarar hur Big Data-industrin trender på dagens marknad och varför du kommer att ha det bättre med en Big Data-karriär under det kommande decenniet.
Den här bloggen förklarar varför du bör anta Big Data & Hadoop-karriär. Det förklarar också löntrenden, nödvändiga färdigheter och tillväxt i Hadoop-karriären.
Den här bloggen diskuterar Hive-kommandon med exempel i HQL. SKAPA, DROP, TRUNCATE, ALTER, SHOW, BESKRIV, ANVÄND, LADDA, INSÄTTA, GÅ MED och många fler Hive-kommandon
Programmerare och dataforskare älskar att arbeta med Python för stora data. Det här blogginlägget förklarar varför Python är ett måste för Big Data Analytics-proffs.
Intresset för Hadoop har ökat till många gånger de senaste åren. Det här inlägget svarar på dina frågor och rensar många tvivel om Hadoop 2.0 och dess användning.
Big Data-träning har trängt in i 7 domäner. Lär dig hur det fungerar genom blogginlägget!
Med Hadoop som både skalbar dataplattform och beräkningsmotor växer datavetenskap ut igen som en central del av företagsinnovation. Hadoop är nu en välsignelse för dataforskare.
I denna Apache Spark & big data-blogg, låt oss se hur man bygger Spark för en specifik Hadoop-version. Vi kommer också att lära oss att bygga Spark för GARN och HIVE.
Scala är ett funktionellt programmeringsspråk som också integrerar objektorienterad programmering. Detta inlägg täcker främst dess funktionella programmeringsfunktioner.
Den här bloggen berättar allt du behöver veta om partitionering i Spark, partitionstyper och hur det förbättrar exekveringshastigheten för nyckelbaserade transformationer.